スクレイピング構想
○どういう情報を取得するか
毎日、定時にその日の予定/話題をメールで受信したい。
私の趣味は、釣り/潮干狩りなので「潮回り」は特に重要です。
※予定は殆ど、テニスの予定(3つのサークルに参加)。
毎日のことなので、いちいちブラウザでGoogleカレンダー、ニュース
サイト、天気&潮回り等、歩きまわりたくはないです。
具体的には、以下の情報を自動で取得したいです:
○本日の天気(含む1週間、含む1時間毎)
○本日は何の日
○潮回り(潮、干潮/満潮時間)
○本日の予定(含む今後の予定)
○本日のTODOリスト(含む今後の予定)
○本日みたいテレビ番組
○昨日のコロナ状況(ワクチン接種率、感染者数)
○本日のニュース
○一日一言
○図書館貸出し期限切れの本(※主テーマは自動ログイン)
○メール受信件数
取得する最終的なデータ
○メールで表示した場合



○ブラウザで表示した場合
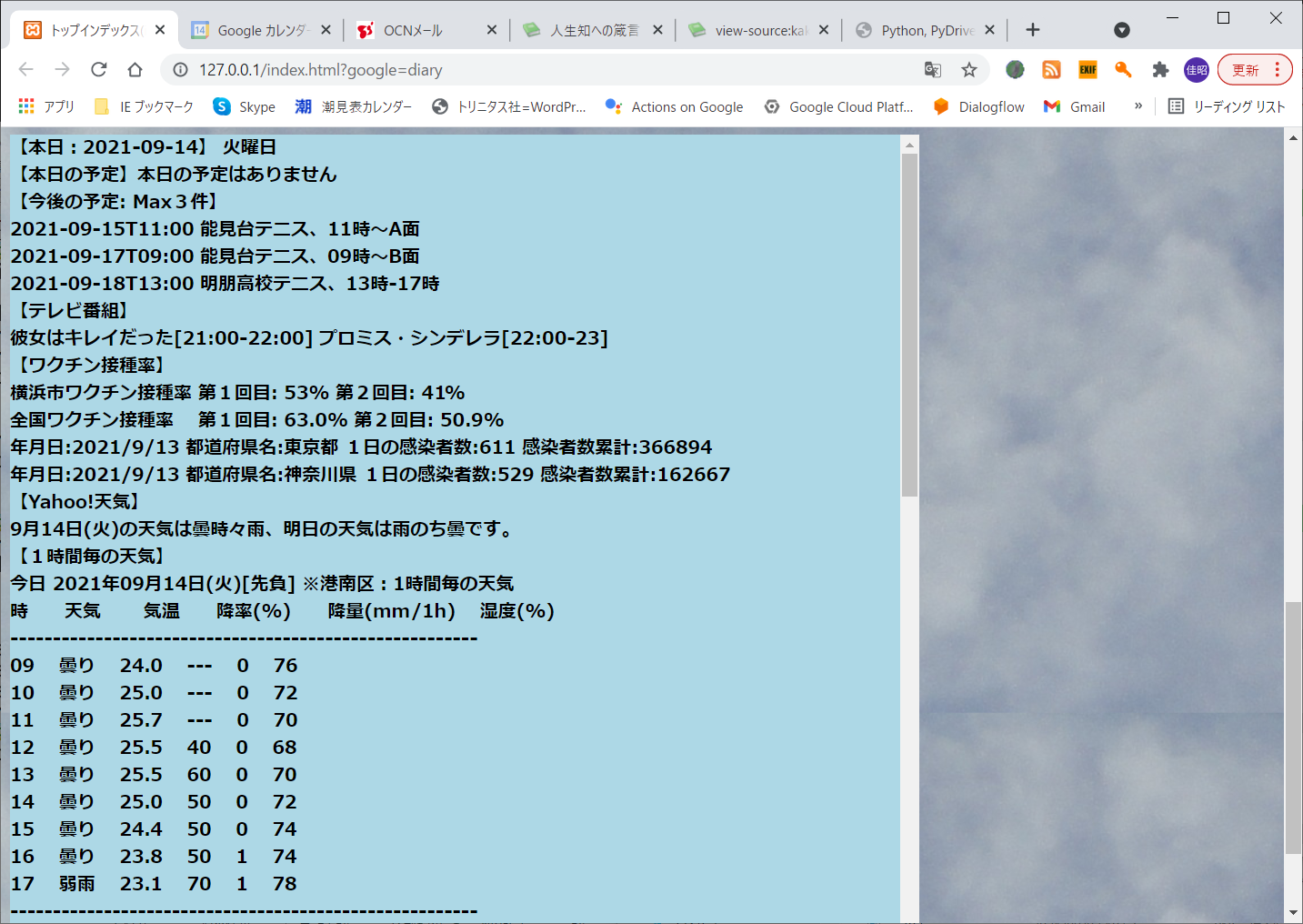


本日の予定と今後の予定
○本日の予定と今後の予定
GoogleカレンダーからGoogleCalenderAPIを通して取得します
当日の内容及び今後の3件を表示します
GoogleAPIの有効化及び認証設定が別途必要です

本日のテレビ番組
○本日のテレビ番組
1週間のテレビ番組(曜日別)をファイル(tv.txt)に登録して該当日のデータを抽出
して表示します

本日の天気(&1週間の天気)
○本日の天気
Yahoo!から天気情報を取得して、本日分を表示します。
1週間分は、「iCal週間天気予報」から取得して、表示(情報のソースが異なる)します
1時間毎の天気も載せます



本日のメモ
○本日のメモ
Google!KeepからGoogleKeepAPI(非公式)を通して取得して表示します
非公式なので通常のアクセスとは異なり、Googleアカウントでセキュリティ設定が
必要となります、設定は以下です:
「設定」「その他の Google アカウントの設定」「セキュリティ」~
①安全性の低い設定
②2段階認証を設定
③アプリのパスワードを設定
現在は、ラベルが「★★★」のみを表示するようにしています。

本日のTODOリスト
Yahoo!TaskからGoogleTaskAPIを通して取得して表示します
GoogleAPIの有効化及び認証設定が別途必要です
※GoogleTODO用APIがあるがpython2系のみサポートでpython3系では使用できません。

本日の潮回り
○本日の潮回り
「潮MieYell」から情報を取得して、本日分のみ表示します。
潮回り(大潮/中潮/小潮等)、満潮/干潮時間、潮高を表示します。
また潮干狩り情報を「○/◎」で表示します。

本日は何の日
今月の祝日、二十四節気、世の中で何があった日かの情報を提供します。



本日までのワクチン接種率
厚生労働省、横浜市から情報を入手して、横浜市及び全国のワクチン接種率を表示
します。
また東京都、神奈川県の新規感染者数も表示します。


本日のニュース
○本日のニュース
Yahoo!ニュースより本日の情報を取得して表示します


1日1言(作成中)
○1日1言(作成中)
世界傑作格言集
雑学・豆知識 特選集 -第一章-
シャッフリングして1日1言を送付します。
320個あるので、本日の通算日をインデックスとして選択します。

図書館貸出し期限切れの本
○図書館貸出し期限切れの本
ここでの技術的なメインテーマは、自動ログインです。
※pythonの「Selenium」ライブラリ及び「ChromeDriver」を使用します。
横浜市中央図書館で借りた本の期限切れ確認
以下の3画面を自動で遷移させます。



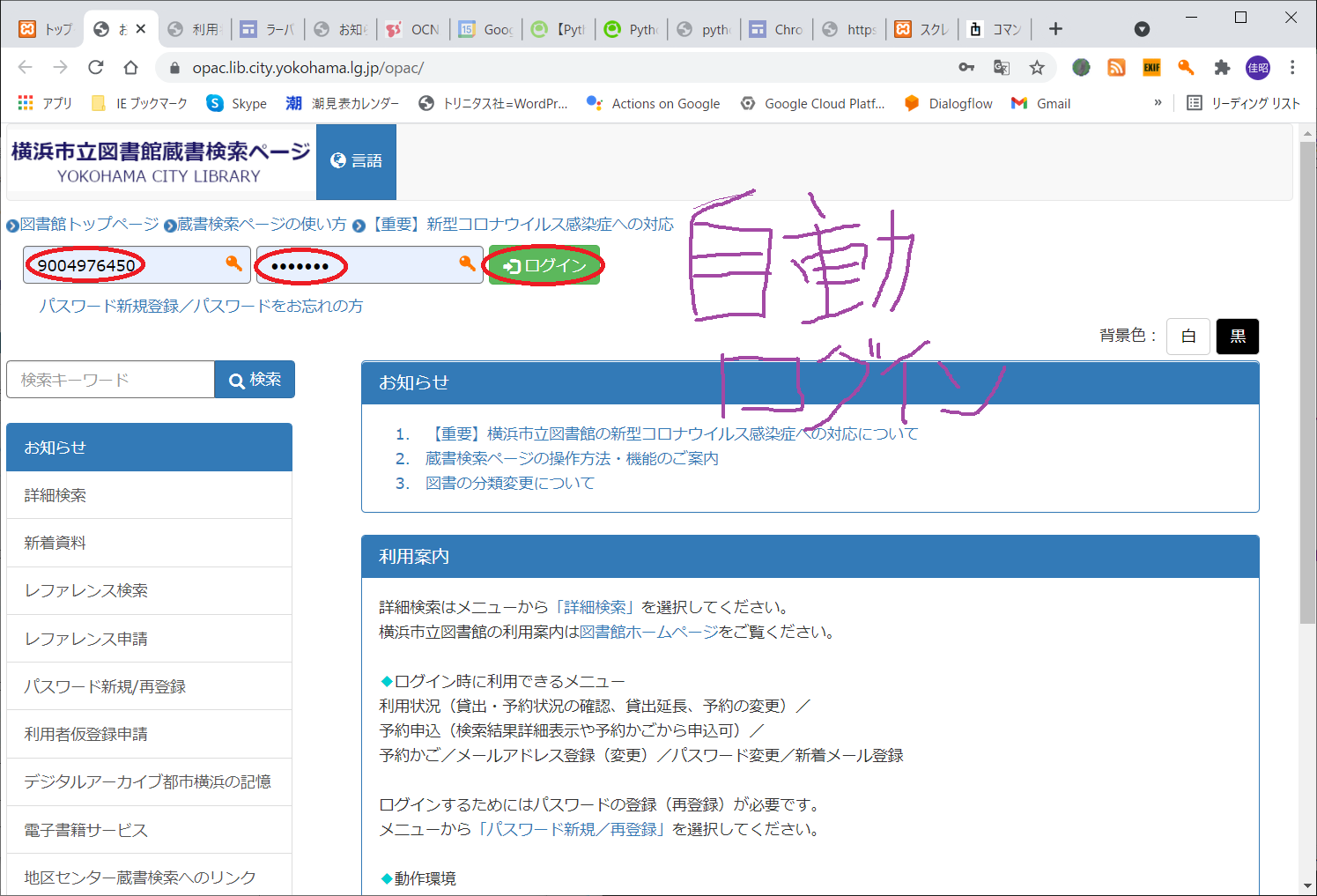
自動ログインの方法 with python
○自動ログインの様子(イメージ)
○「図書館カード番号」を自動入力します
○「パスワード」を自動入力します
○「ログイン」ボタンを自動押下します
○「ログイン」状態になったら、左ペインの「利用状況」を自動押下します
○貸出中、予約中の本が表示されます。
○自動ログインの方法 with python
ここでは横浜市中央図書館への自動ログイン方法を記します
○インストールするもの
Google Chrome上でSeleniumをPythonで実行するにはまず下記をインストールする必要があります。
○Python(v3.x推奨)
○Selenium pip install selenium
○Chrome Driver 手動でインストール、Chrome Driverインストールを参照
○HTMLの表示方法
以下の3つの方法を説明します:
①ブラウザのソース表示機能
②開発ツールでソース表示機能
③pythonで表示プログラムを作成
※詳細は別途、説明します。
○HTMLの解析方法
以下の3点を解析します:
①ユーザID(user)を入力しますinputタグ
②パスワード(password)を入力しますinputタグ
③ログインを実行します(submit)buttonタグ
※解析内容は、タグに所属する「name」/「id」属性です。これがない場合は_xpathを使用します。
※詳細は、後述の「ChromeブラウザでHTMLを解析します:を参照
○ChromeDriver のインストール:
以下のサイトからChromeDriverを入手します:ChromeDriver 93.0.4577.63
https://chromedriver.chromium.org/downloads
https://chromedriver.storage.googleapis.com/index.html?path=93.0.4577.63/
⇒Windowsのものは「chromedriver_win32.zip」、64bitだが動作しました
⇒使用しているChromeブラウザのバージョンは「93.0.4577.82」(64 ビット)
なお私は、ダウンロードしたzip(chromedriver_win32.zip)を解凍して生成された「chromedriver.exe」を
直接anaconda環境に手動で設定しましたが、環境変数PATHに設定したほうがスマートです。
※C:\Users\shim1\anaconda3\Lib\site-packages\chromedriver_binary配下にコピー

なおインストールしたChromeDriverのバージョンは、ダブルクリックすると確認できます。
また、表示されたウィンドウを終了するには「Ctrl+C」です。
○ChromeブラウザとChromeDriverのバージョンは合わせないとエラーとなります
例えば、当初は以下のエラーが発生し例外が発生しました。
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.SessionNotCreatedException: Message:
session not created: This version of ChromeDriver only supports Chrome version 94
Current browser version is 93.0.4577.82 with binary path C:\Program Files (x86)\Google\Chrome\Application\chrome.exe
○他のブラウザの場合(ブラウザドライバ)

他のブラウザの場合、以下のURLから自分のブラウザに合うドライバをダウンロードして下さい。
https://www.selenium.dev/ja/documentation/getting_started/installing_browser_drivers/
○※ChromeブラウザでHTMLを解析します
ユーザID(900497….)のHTML要素を解析します場合::




メソッド:
browser.find_element_by_id()
browser.find_element_by_name()
driver.find_element_by_class_name()
browser.find_elements_by_css_selector()
browser.find_element_by_xpath
例:
CSSセレククタ:「Copy」「Copy selecter」
#inlinelogin_form > input:nth-child(1)
XPath:「Copy」「Copy XPath」
//*[@id=”inlinelogin_form”]/input[1]
メール受信件数
OCNメール受信箱のメール件数

上記の内容をメール送信します
OCNのSMTPを利用して、上記で取得した内容を、毎日定時に送信します。
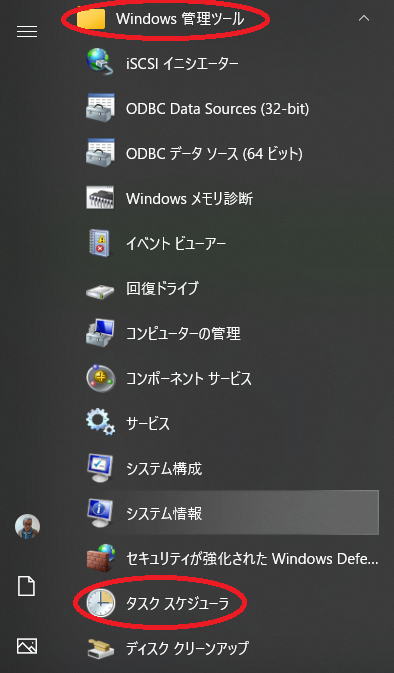
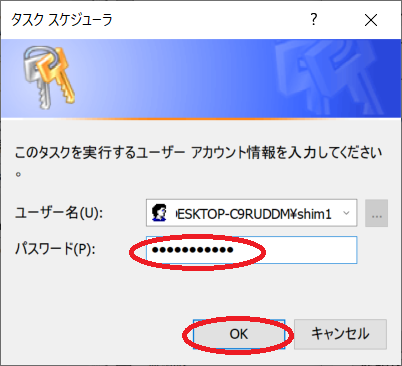
定時実行は、Windows10のタスクスケジューラを利用します。
Windows10スケジューラ
Windows10のタスクスケジューラでの登録方法です。

○新しいタスクの作成方法








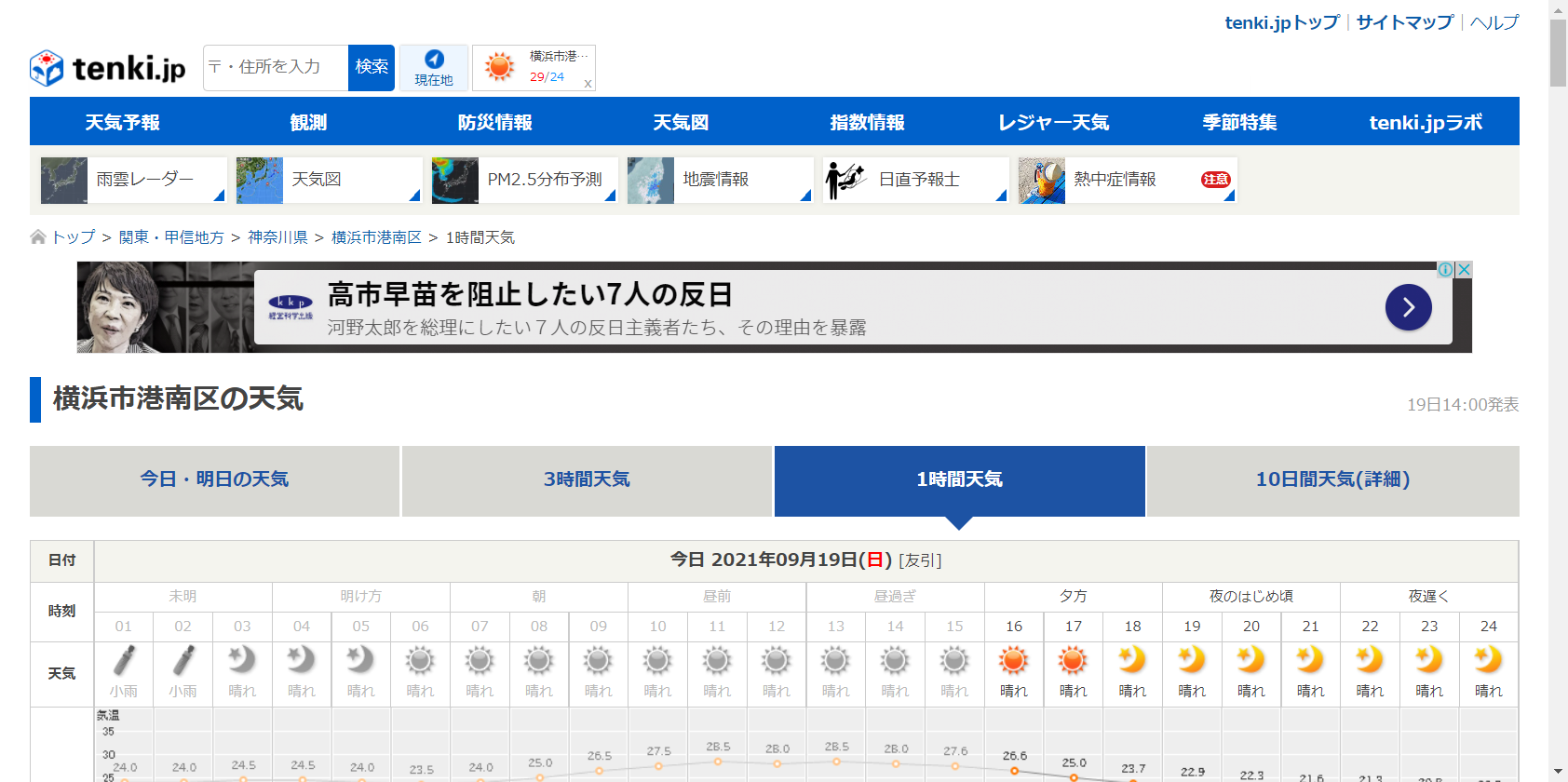
WEBページのキャプチャ[capture.py]
○おまけ(^_^)
実際にキャプチャしたWEBページ(1時間毎の天気)
著者:志村佳昭(株式会社トリニタス 技術顧問)